Disrupting the Codebase: Why Agile Enterprises Are Moving to Visual AI Orchestrators
The case for no-code AI automation as a strategic delivery methodology — not a workaround
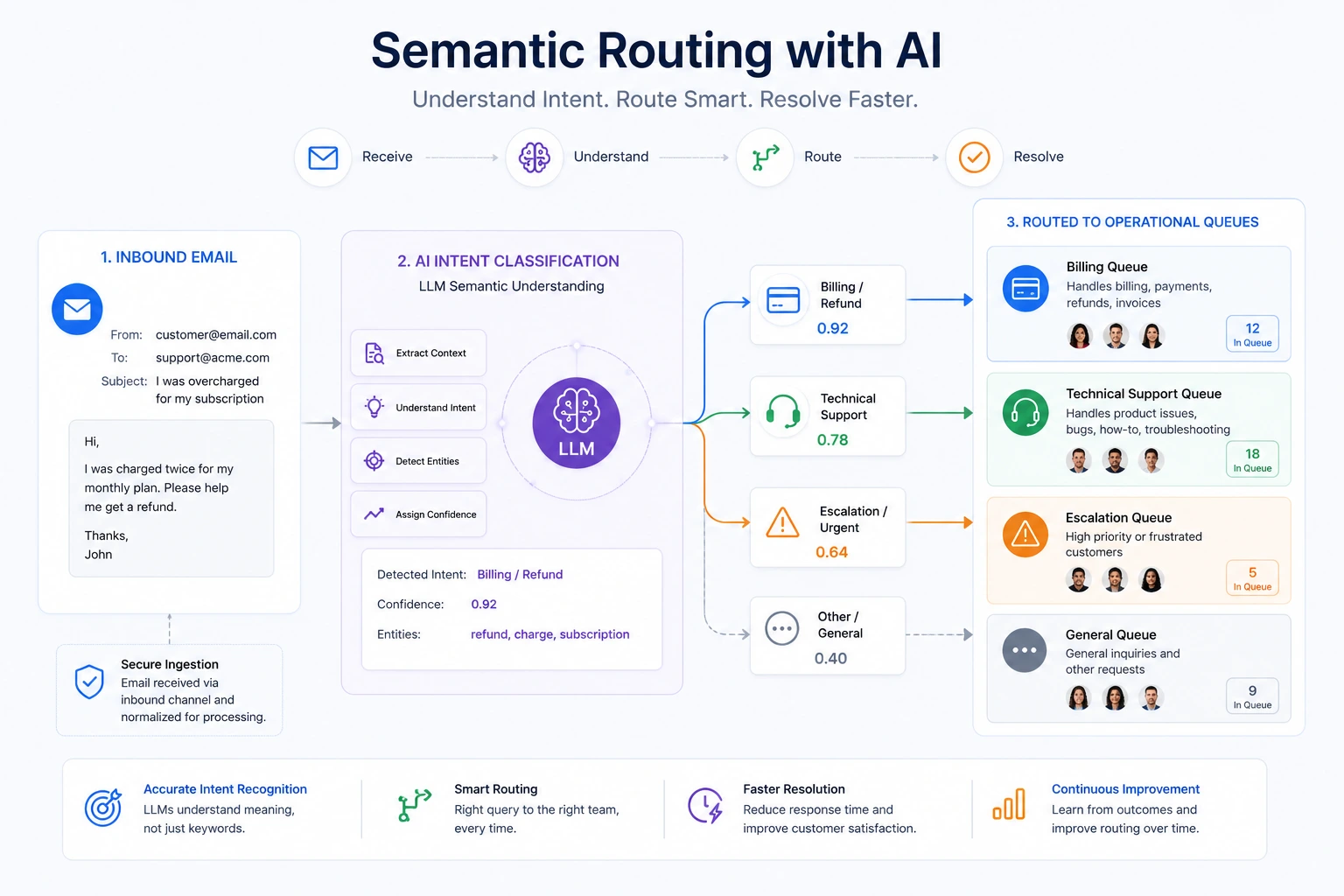
The conventional approach to enterprise middleware has always been the same: identify a business process, write a specification, assign a development team, wait through a sprint cycle, test, deploy, and maintain. This loop — expensive, slow, and heavily dependent on engineering bandwidth — was never optimized for the speed at which modern business conditions change. When a procurement process needs a new approval tier, or a customer intake flow needs to account for a new compliance requirement, the traditional stack cannot respond quickly enough to match operational reality.
Visual AI orchestrators solve this by compressing the delivery cycle from weeks to hours. When an Operations Director can describe a data flow visually, connect it to a live API, and deploy it by end of business — without a pull request, a code review, or a staging environment — the organization’s ability to respond to change becomes a structural advantage rather than a periodic project.
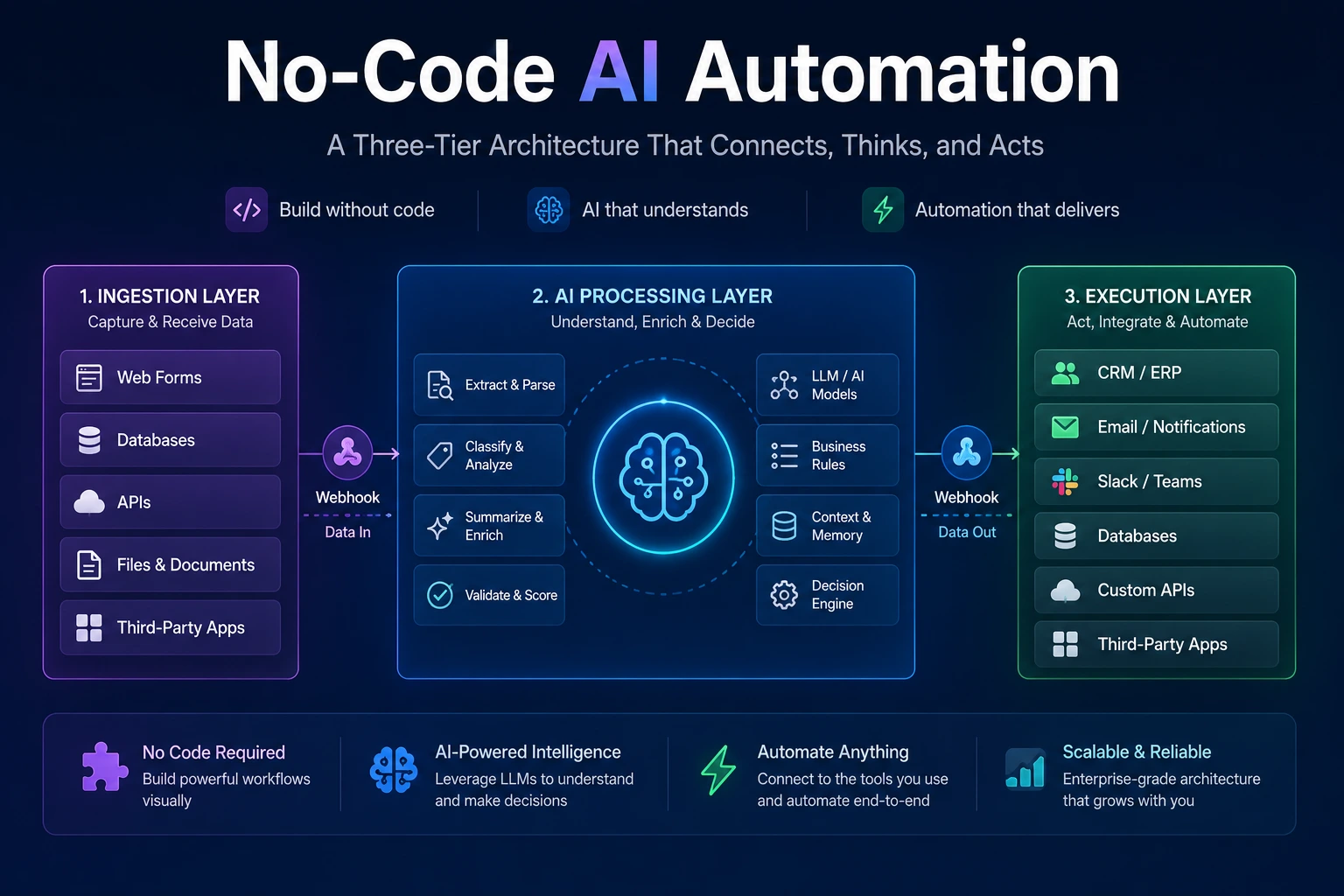
I want to be explicit about what this is not. No-code AI automation does not replace software engineering for product development, custom application logic, or algorithmic computation. What it replaces is the heavy, custom-coded middleware layer that most organizations have historically built to move data between SaaS systems, trigger actions based on business rules, and generate outputs from structured inputs. That layer — the connective tissue of the enterprise stack — is where visual builders with embedded LLM nodes are now operationally superior.
💡 The Agile Framing That Changes Everything
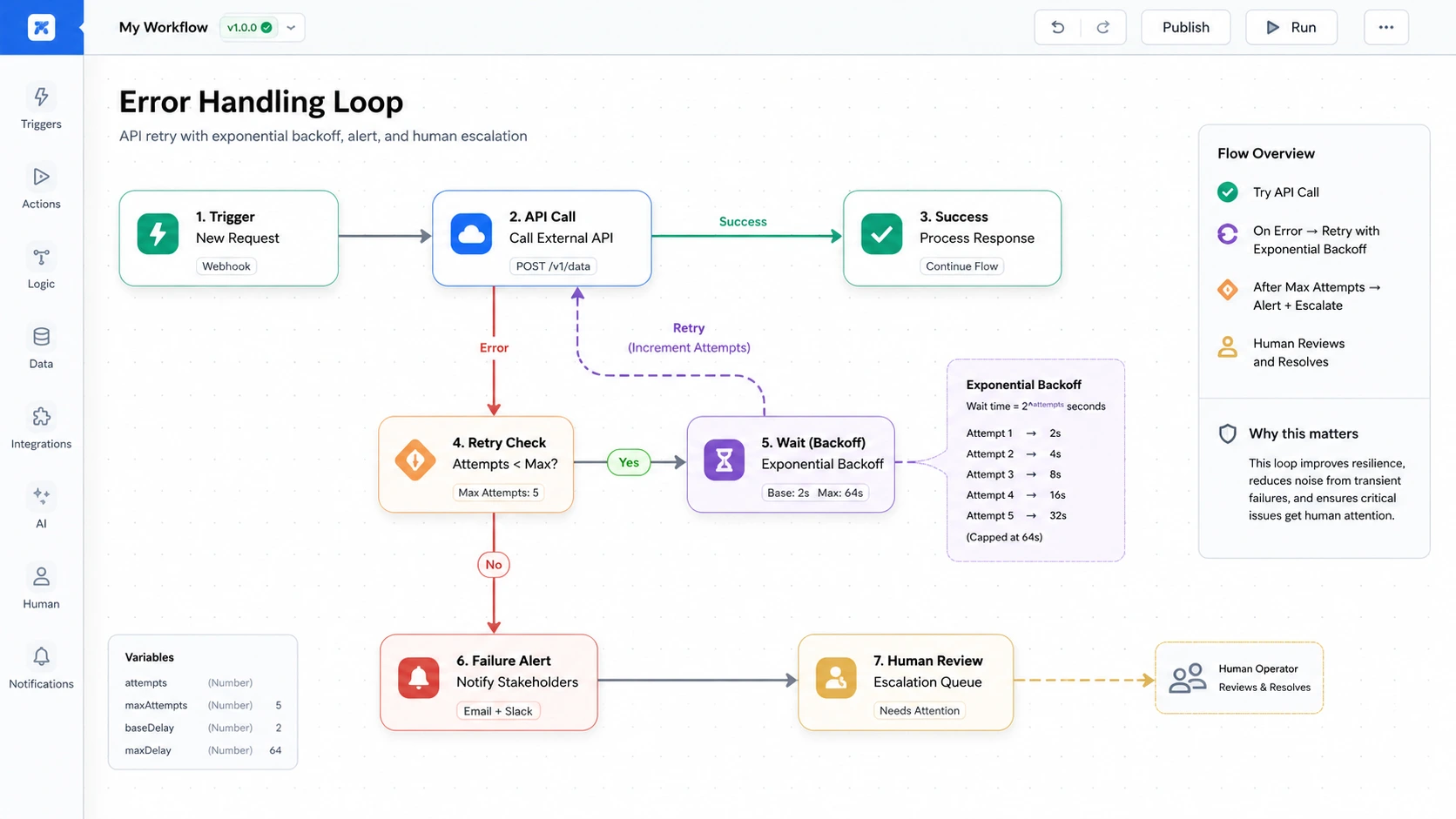
Frame no-code AI automation as an agile software delivery method, not a tool category. When leadership understands that a visual pipeline is a deployable system with version history, audit logs, and structured error handling — and not a spreadsheet macro — the conversation about enterprise adoption changes entirely.