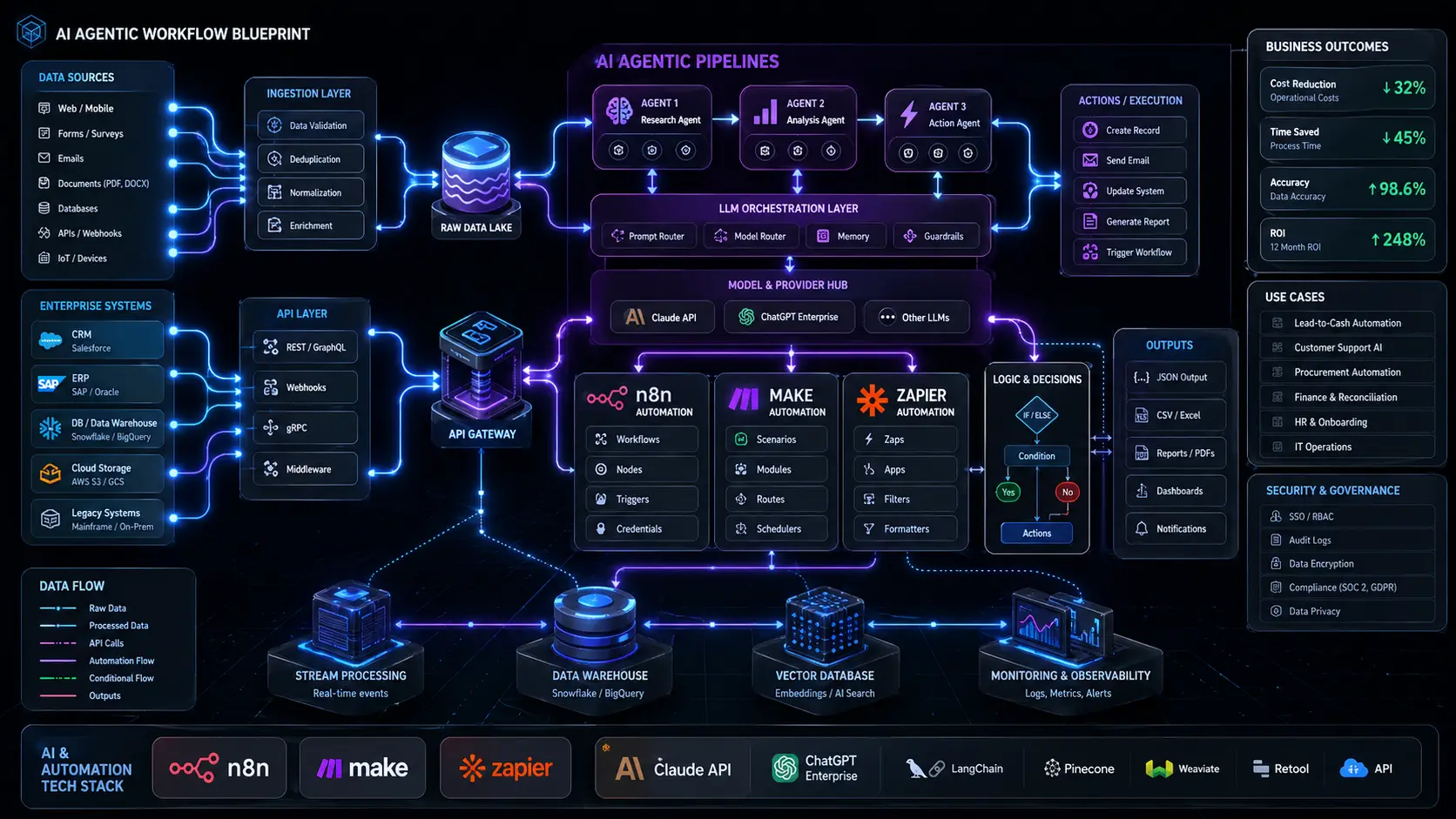
n8n — Orchestrating Enterprise AI Tools for Sensitive Data
Best for: data-sensitive enterprises, complex multi-step agentic pipelines, API-heavy integrations
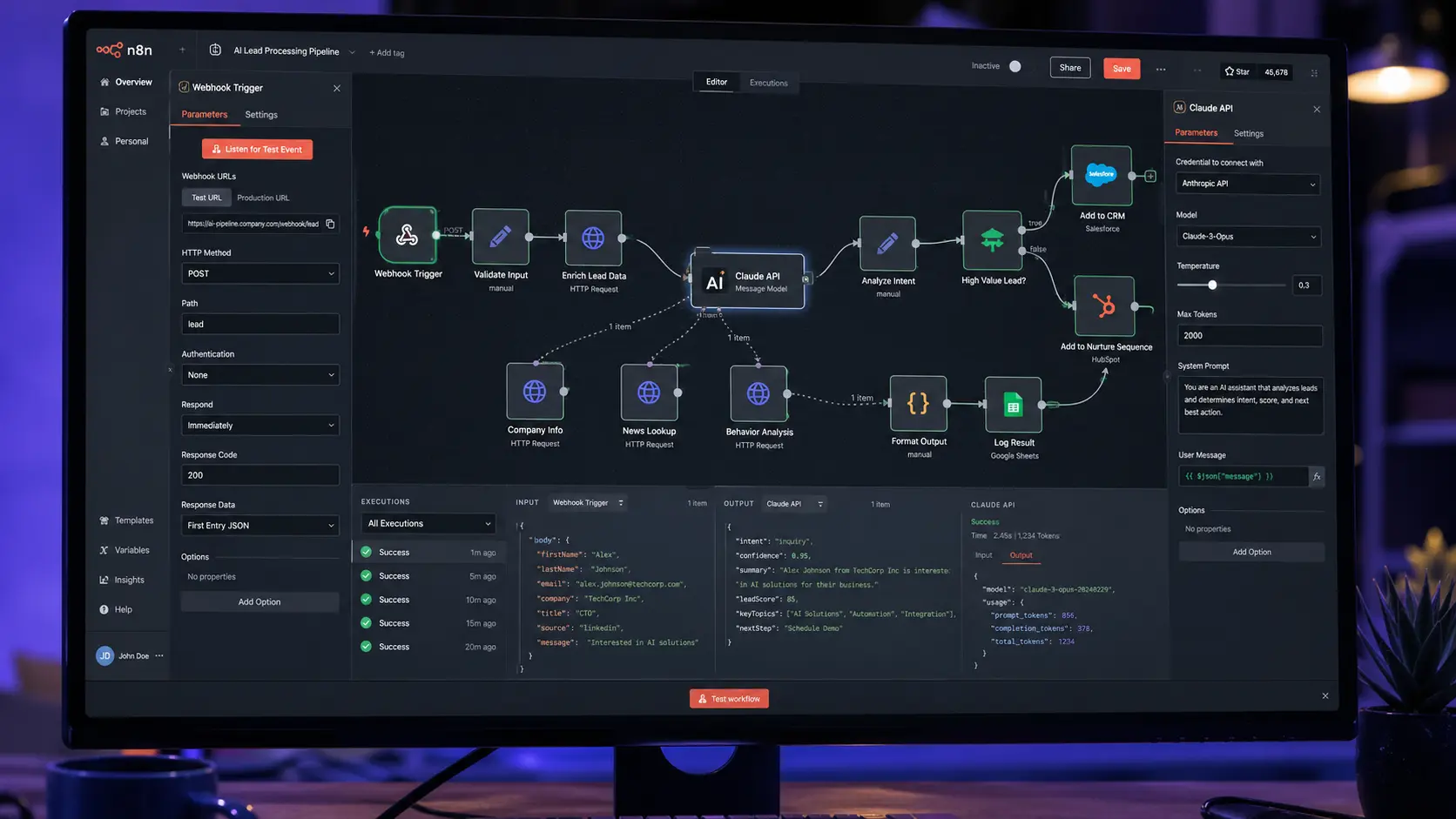
n8n is the most architecturally serious tool in this list for enterprises that need to own their infrastructure. Unlike SaaS automation platforms, n8n can be self-hosted on your own server or VPC, meaning no customer data leaves your perimeter before you’ve explicitly decided it should. Its node-based visual editor supports complex conditional branching, webhook triggers, HTTP request nodes for raw API calls, and native LLM integrations with OpenAI, Anthropic, and Ollama.
The real power emerges when you chain LLM nodes with data transformation steps. A practical architecture for automated invoice processing: an IMAP email trigger fires when a new PDF arrives, a Code node extracts the attachment, an HTTP Request node sends it to the Claude API for structured JSON extraction (vendor name, invoice number, line items, total), a Switch node routes based on invoice value thresholds, and a final node writes the parsed data to your ERP via webhook.
Trigger: IMAP / email webhook receives PDF attachment → Extract: Code node strips binary, base64-encodes → LLM Call: Claude API with structured extraction prompt → Parse: JSON node validates schema → Route: Switch node on invoice value → Write: HTTP POST to ERP webhook endpoint
Node.js 18+, Docker for self-hosted deploy, outbound HTTPS to LLM API endpoints, webhook URL accessible for inbound triggers, API keys stored as n8n credentials (never in workflow JSON). For PDF parsing, pair with a Tika or pdfplumber sidecar service.
💡 Architecture Note
n8n’s “AI Agent” node supports tool-calling loops natively — it will re-call tools until a stopping condition is met, enabling genuine agentic behavior without custom code. Use this for workflows where the LLM needs to query a database, check an API, and make a decision before writing a result.
⚠️ Honest Limitation
n8n’s error handling for long-running agentic loops requires careful configuration. Without explicit retry logic and timeout guards, a stuck LLM call can block an execution indefinitely. Build dead-letter queues and alert webhooks into any production workflow from day one.