The Anatomy of Agentic AI Security
Why autonomous agents need strict guardrails — and how those guardrails differ from traditional IT security
A traditional software system executes deterministic instructions. An agentic AI system makes probabilistic decisions. That distinction has profound security implications. You can formally verify a function’s behavior. You cannot formally verify what a language model will do when its input is an adversarially crafted document embedded inside an otherwise legitimate email thread.
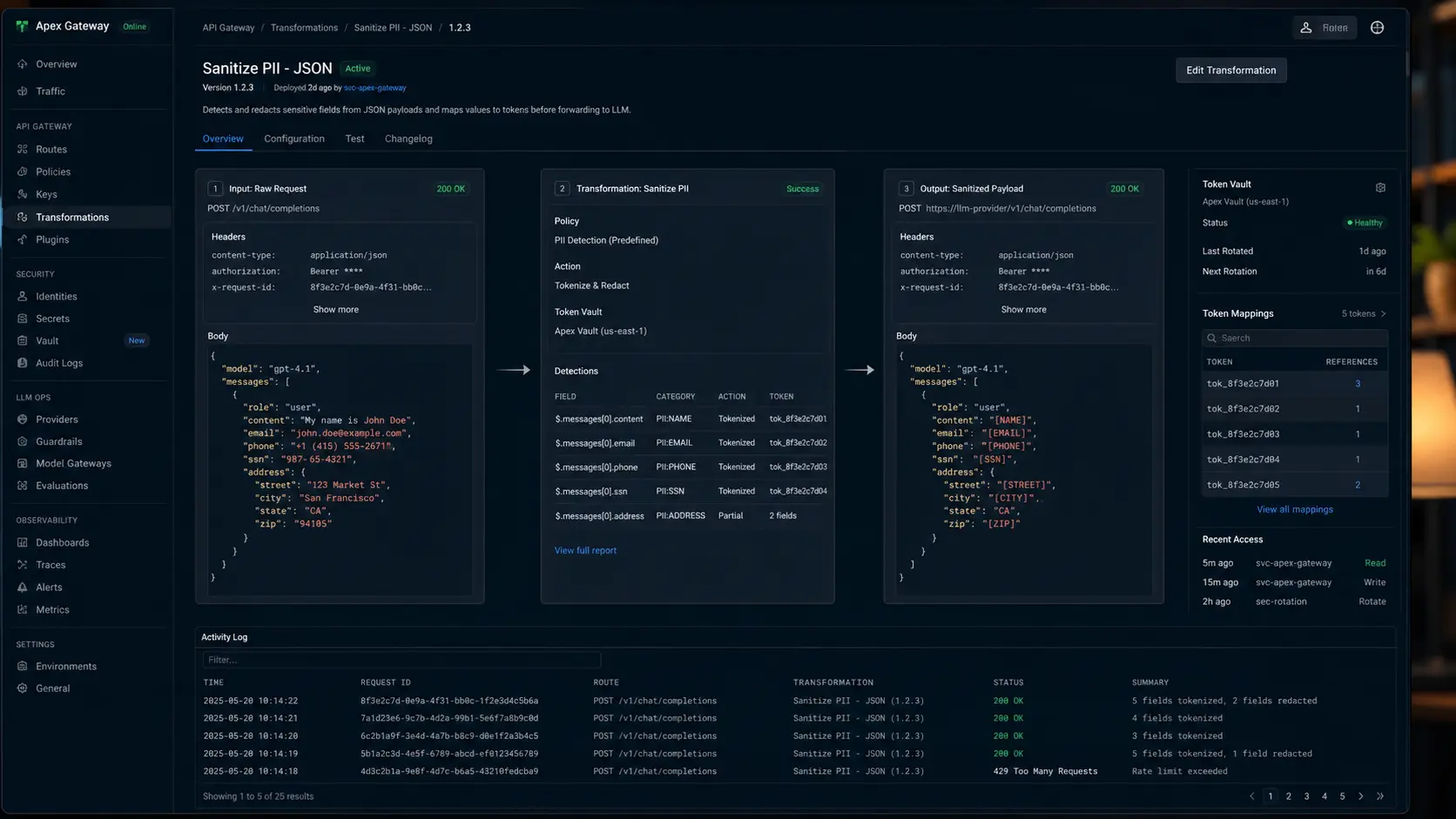
Agentic security requires controls at four layers: data ingestion (what goes into the agent), tool access (what systems the agent can reach), action authorization (which outputs the agent can execute autonomously versus which require approval), and observability (a complete audit trail of what the agent did, why, and with what data). Weaknesses in any one layer create exploitable gaps across the whole stack.
All inputs entering the agent’s context window must be treated as potentially hostile. This includes customer emails, uploaded PDFs, web scrape results, and database query returns. An agentic security system validates and sanitizes each input type before it reaches the model.
Each agent should be issued a scoped API credential with the minimum permissions required for its designated task. An agent that summarizes support tickets has no legitimate need for write access to the billing database. Role-Based Access Control at the agent identity level is non-negotiable in any enterprise AI deployment.
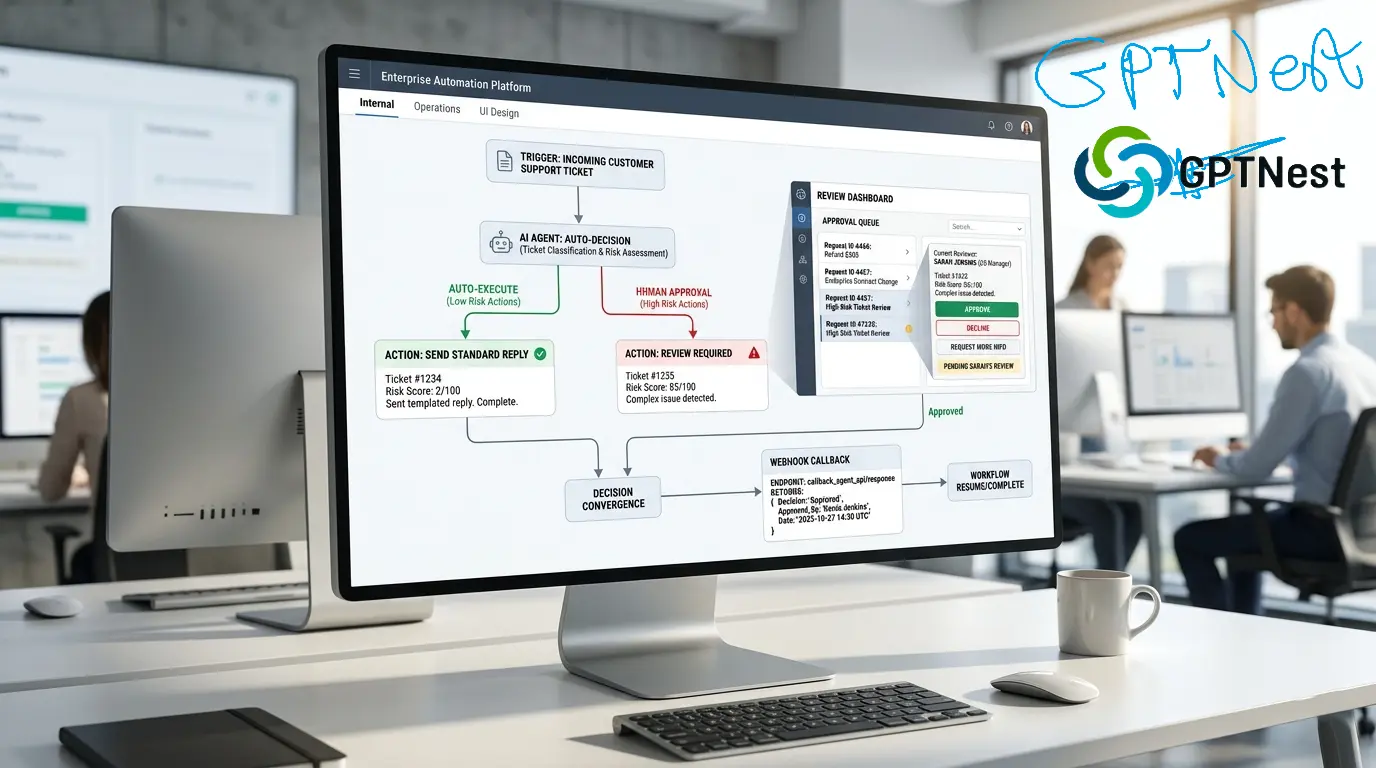
Not all agent outputs are equivalent. Reading a record is low risk. Sending an email to 40,000 customers is not. A security-conscious architecture classifies every tool an agent can call by risk level and applies appropriate authorization requirements — fully autonomous, human-reviewed, or fully blocked — at each tier.
Every agent execution should produce a structured log: inputs received, tools called, data accessed, outputs produced, and any reasoning steps exposed by chain-of-thought prompting. This log is your incident response foundation and your compliance evidence. Without it, you’re operating blind.
💡 Architecture Principle
Design each agent around a security contract: a formal specification of which data sources it can read, which tools it can call, which action classes require human approval, and what it must log. Review this contract before deployment, not after an incident.