The Shift to Advanced Visual Builders — n8n Tutorial vs. Make
Why cost-per-task and linear flows are the real bottlenecks at scale
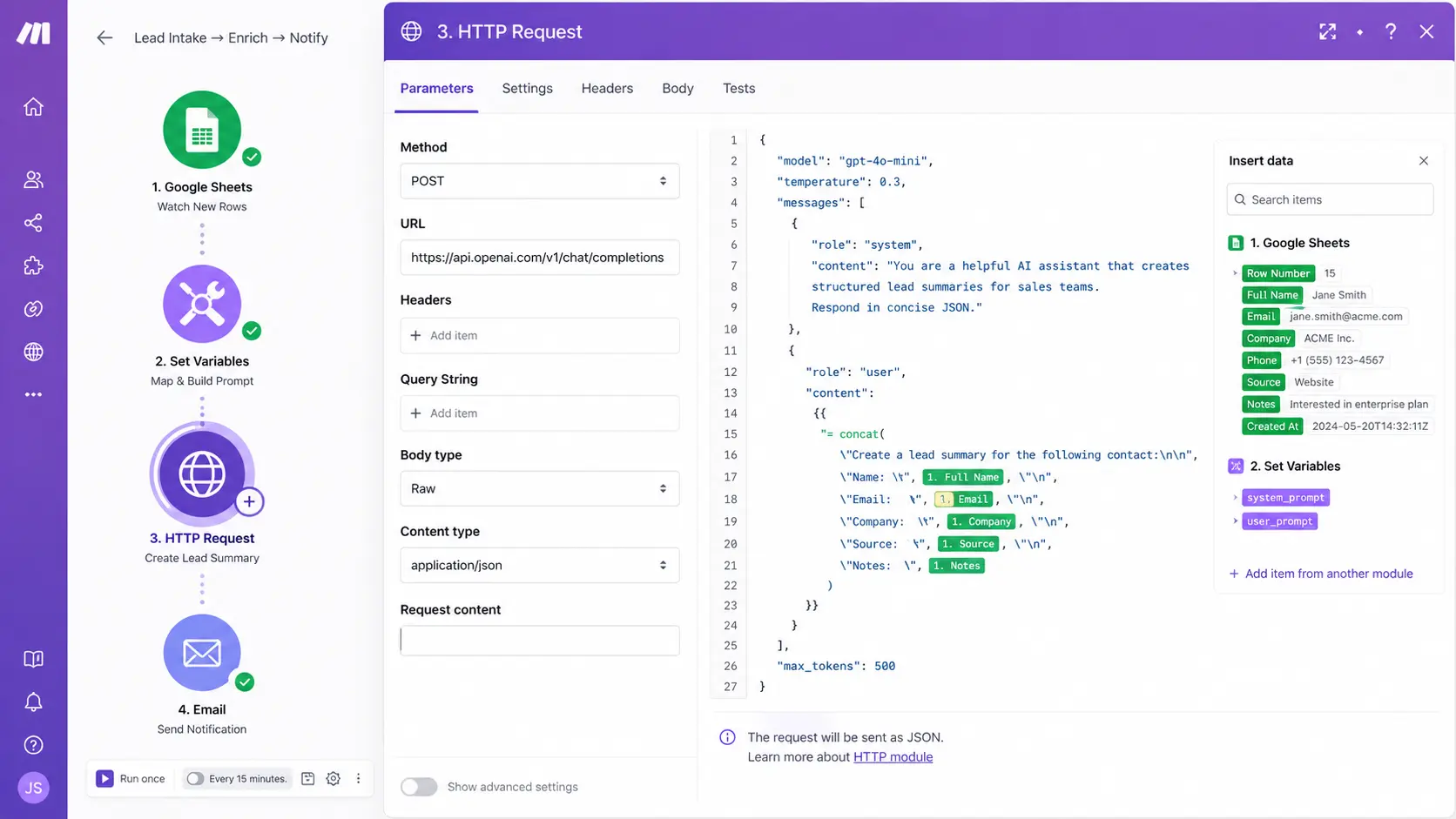
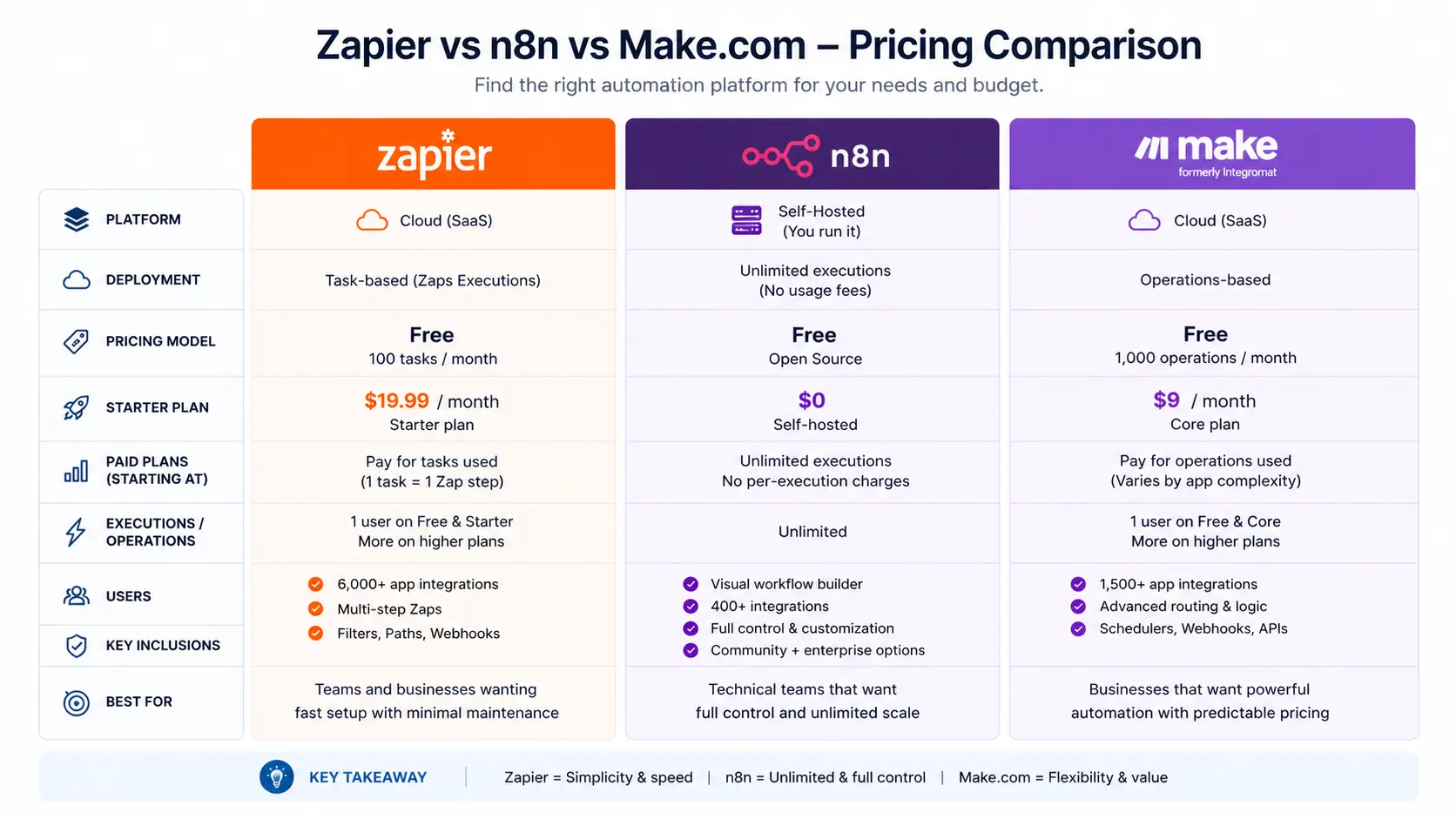
The fundamental issue with tools like Zapier at scale isn’t capability — it’s architecture and pricing. Zapier charges per task execution. Run a five-step Zap 10,000 times a month and you’re consuming 50,000 tasks. That number climbs fast in any real B2B operation. More importantly, Zapier’s linear, trigger-action model becomes a constraint when your actual business logic requires branching: “if the lead’s company size is over 50, route to enterprise sales; if it’s under 10, send to the self-serve sequence; otherwise, flag for manual review.”
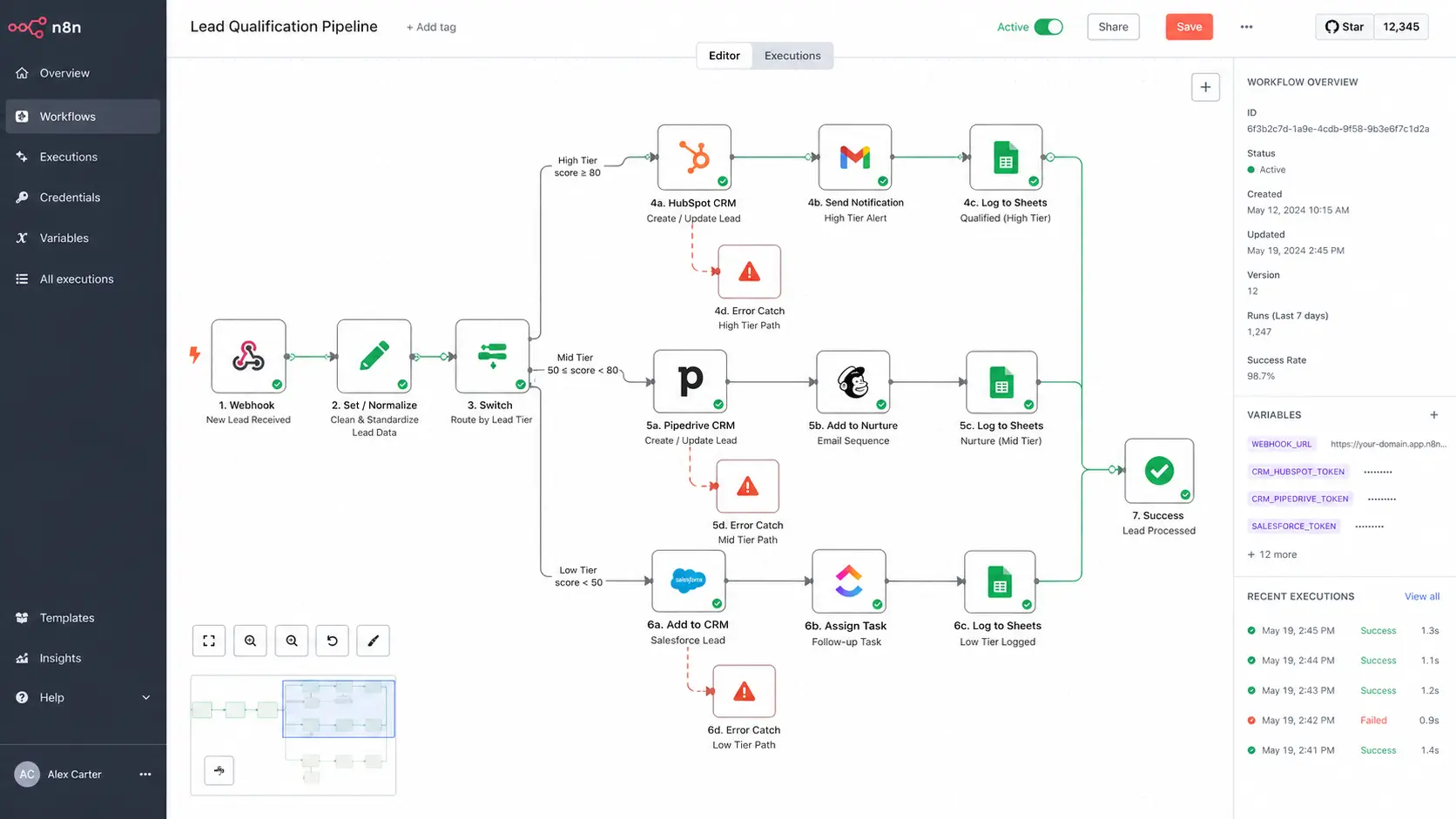
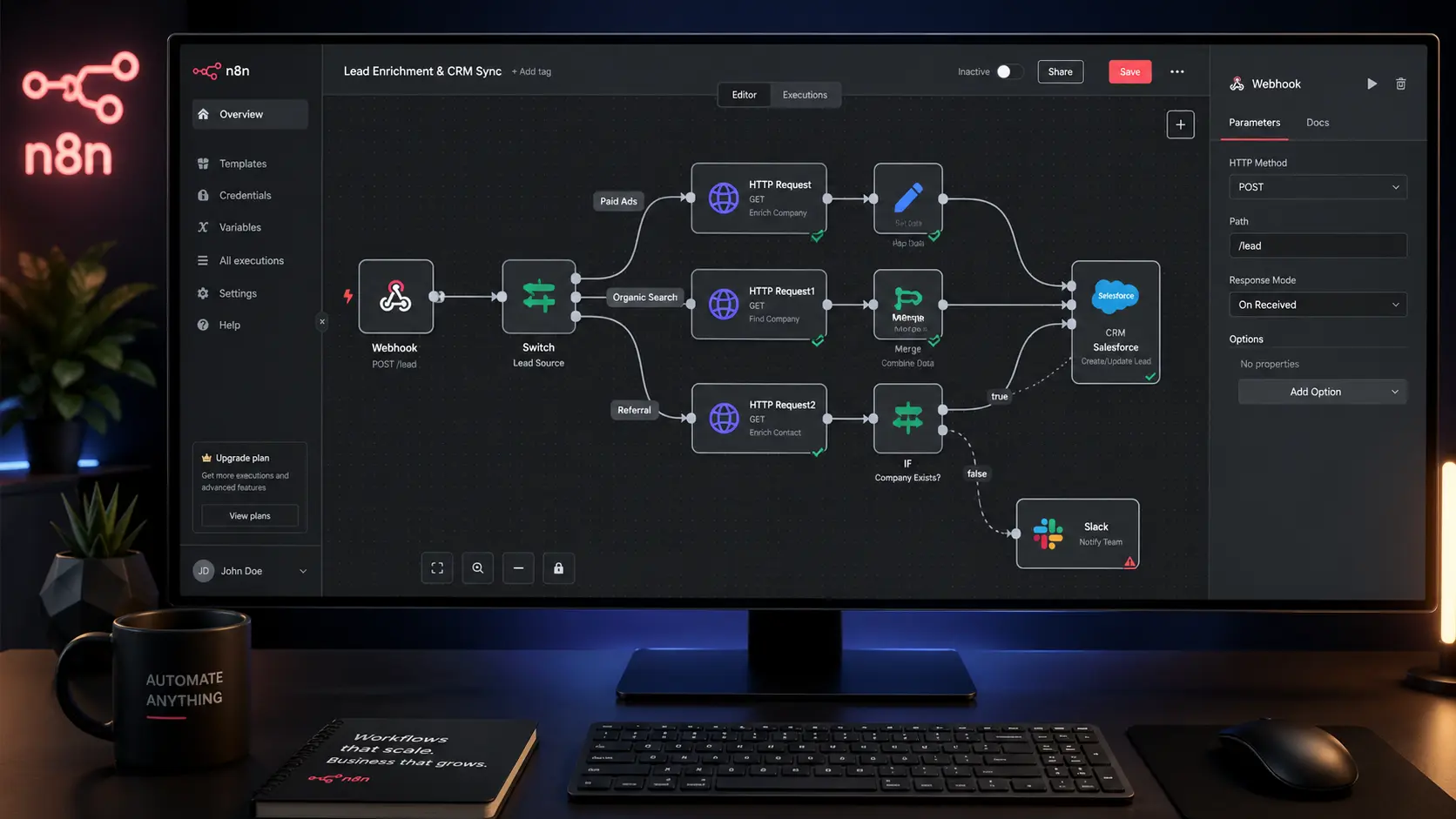
Both n8n and Make.com solve these problems differently. Make operates on a scenario-based model with visual branching, built-in iterators, and a module library that covers nearly every SaaS API. Its HTTP Request module handles raw API calls with full JSON body mapping — no integration required if the endpoint exists. n8n goes further: it’s open-source, can run entirely on your own infrastructure, and supports JavaScript expressions at the node level, which gives you programmatic control inside a visual canvas.
Teams who want a managed cloud platform with extensive pre-built integrations, clean visual scenario design, and predictable monthly pricing based on operations (not per-zap task). Strong for agencies managing multiple client accounts with role-based access.
Technical teams who need full data sovereignty, custom JavaScript logic inside nodes, or are building automation infrastructure for clients in regulated industries. Self-hosted n8n has no execution limits — only your server resources constrain throughput.
💡 Key Insight
The decision between Make and n8n isn’t purely technical — it’s an operational question. If you’re managing automation for clients, Make’s multi-account structure and UI are easier to hand off. If you’re building internal infrastructure where data privacy or unlimited execution scale matters, n8n self-hosted is the correct architectural choice.