4
3 High-Value Enterprise Automation Blueprints
Production-validated agentic workflow designs for operations teams
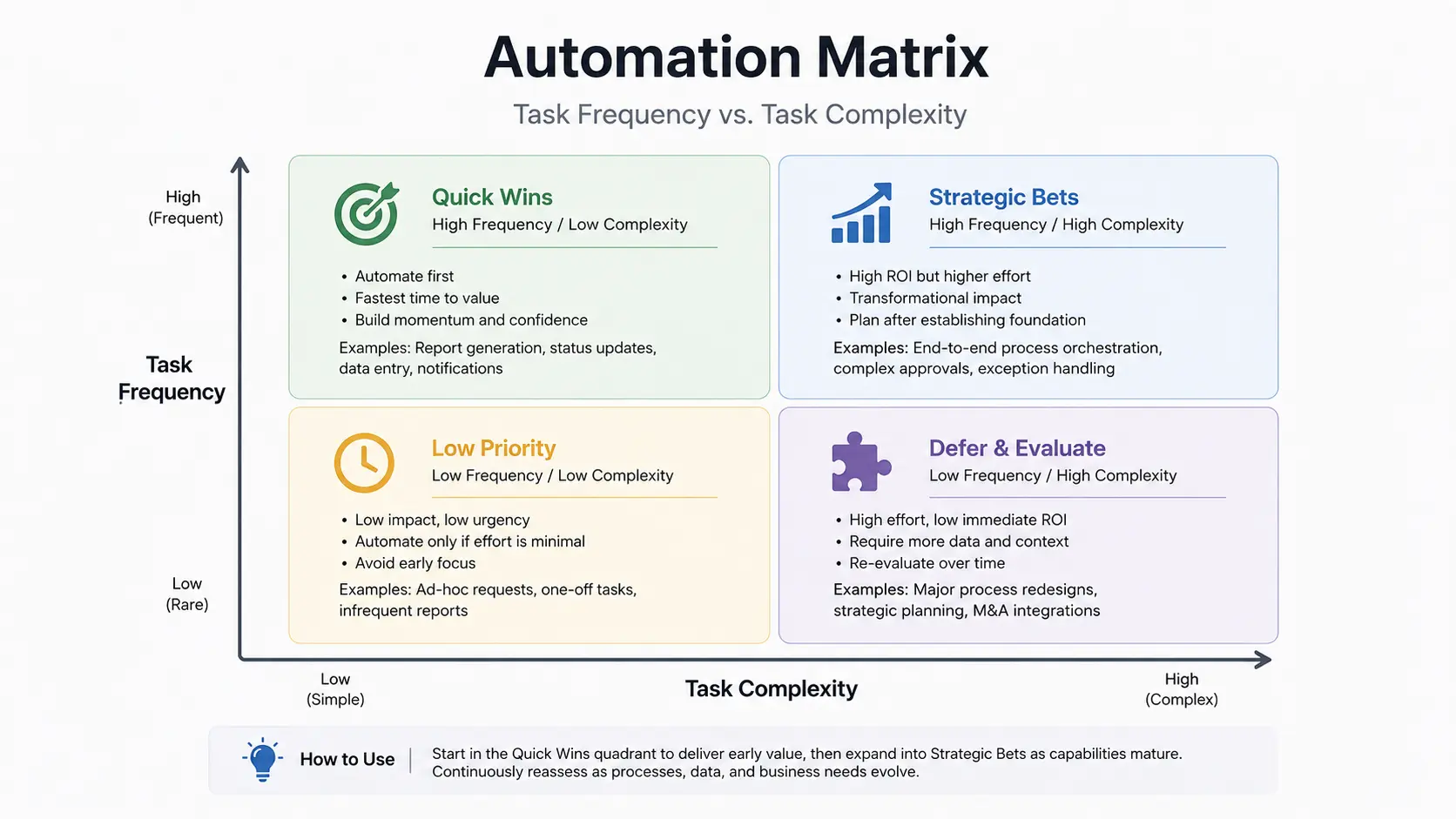
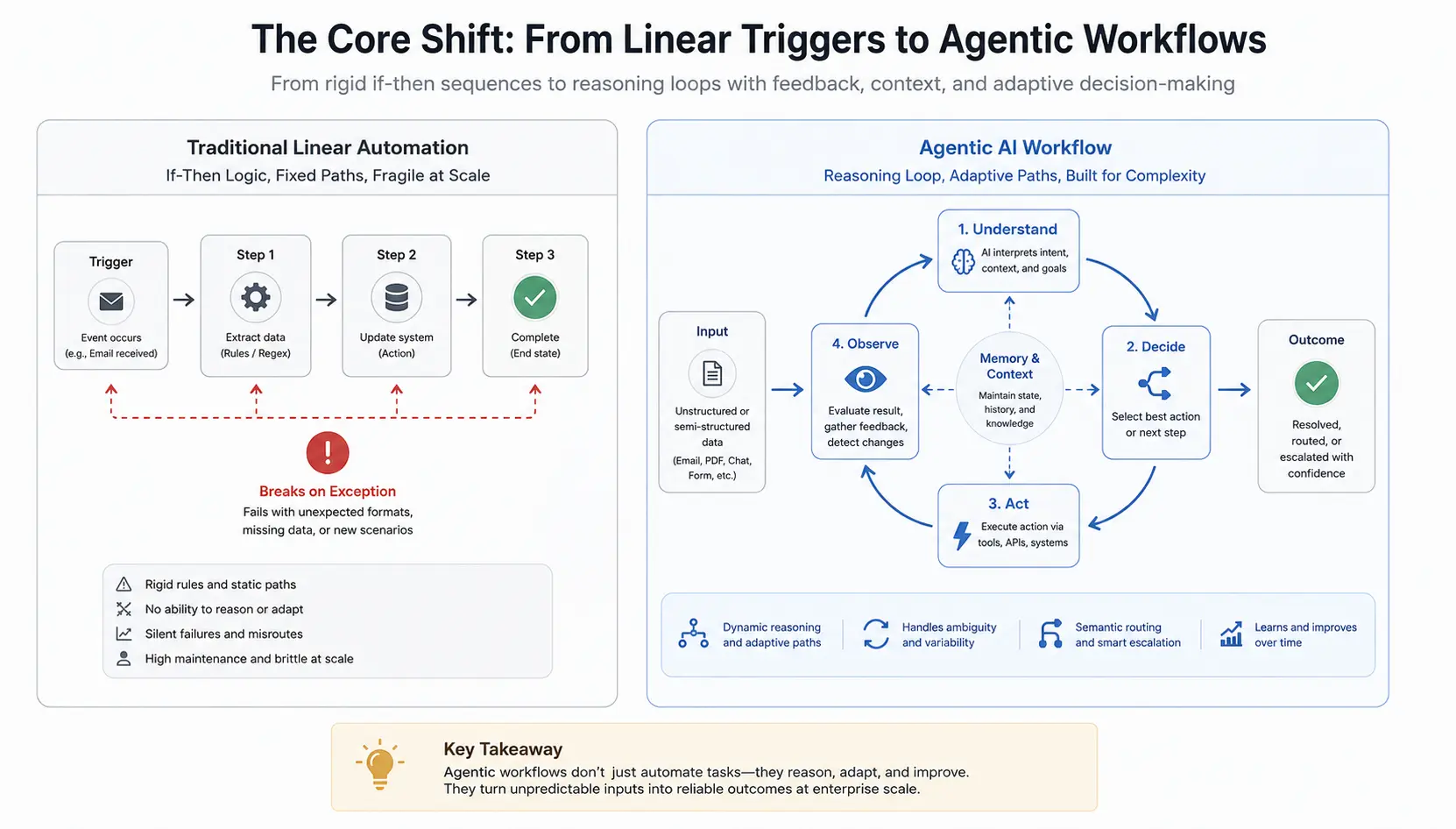
These three blueprints represent the highest-ROI automation targets across the operations teams I’ve worked with over seven years. Each has been validated in production environments and addresses a task category where the mandate to automate repetitive tasks with AI creates exactly the bottleneck that agentic systems resolve.
Blueprint 1 Intelligent Invoice & Expense Reconciliation
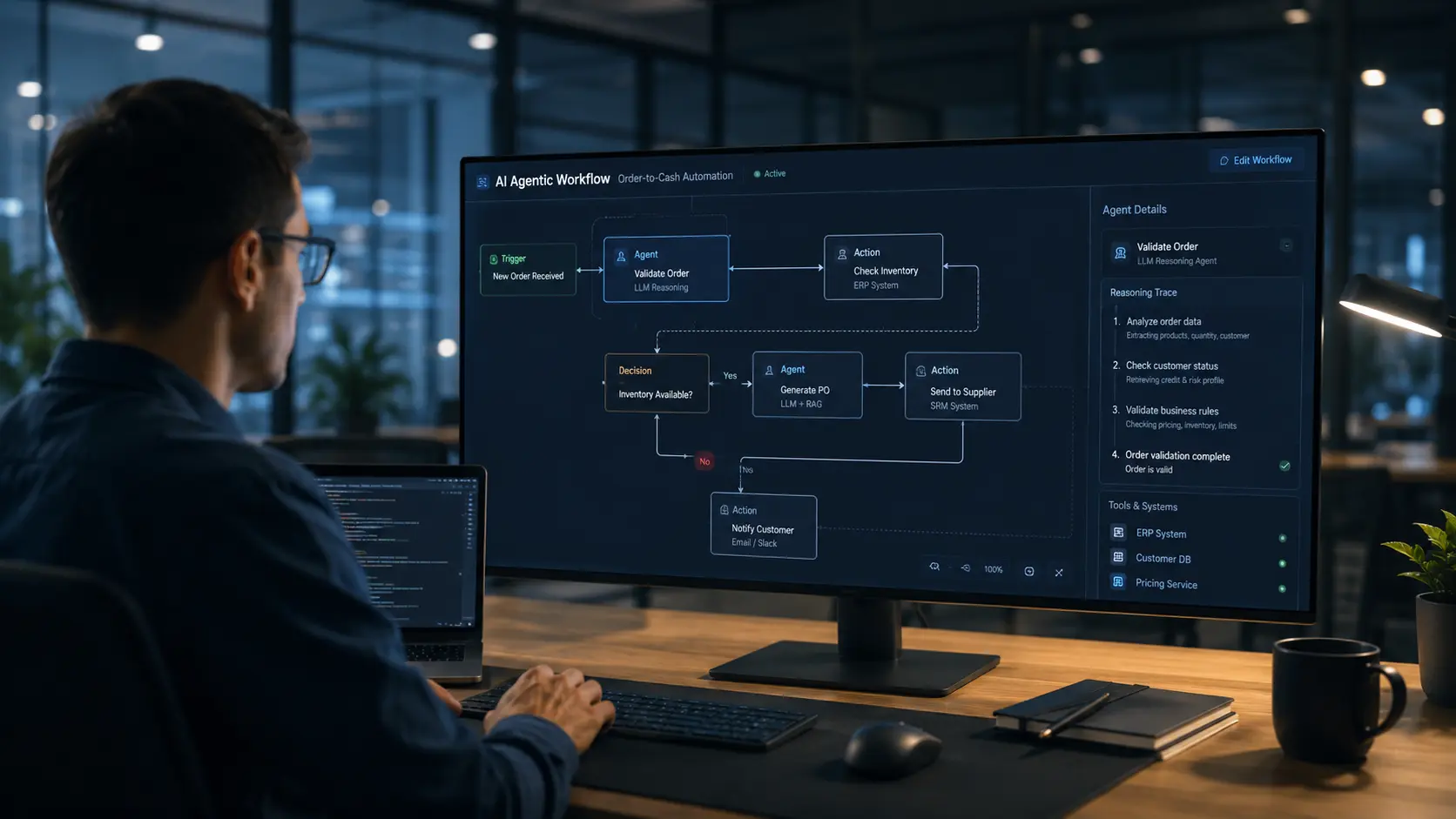
Invoice processing is the canonical agentic automation use case because the inputs are high-frequency, semi-structured (PDFs with variable layouts), and the downstream consequences of errors — incorrect payments, missed discounts, duplicate charges — are financially material. A finance team processing 500 invoices per month manually is spending 40–60 hours on extraction, matching, and exception handling. An agentic system reduces that to under 4 hours.
Ingestion
Invoices arrive via email attachment or vendor portal upload. n8n monitors the inbox, extracts the PDF attachment, converts to text via a document parsing service (Textract, Azure Document Intelligence, or open-source alternatives).
LLM Extraction
The extracted text is passed to an LLM with a schema prompt: extract vendor name, invoice number, line items (description, quantity, unit price), total, due date, and purchase order reference if present. Output is validated JSON.
Matching & Routing
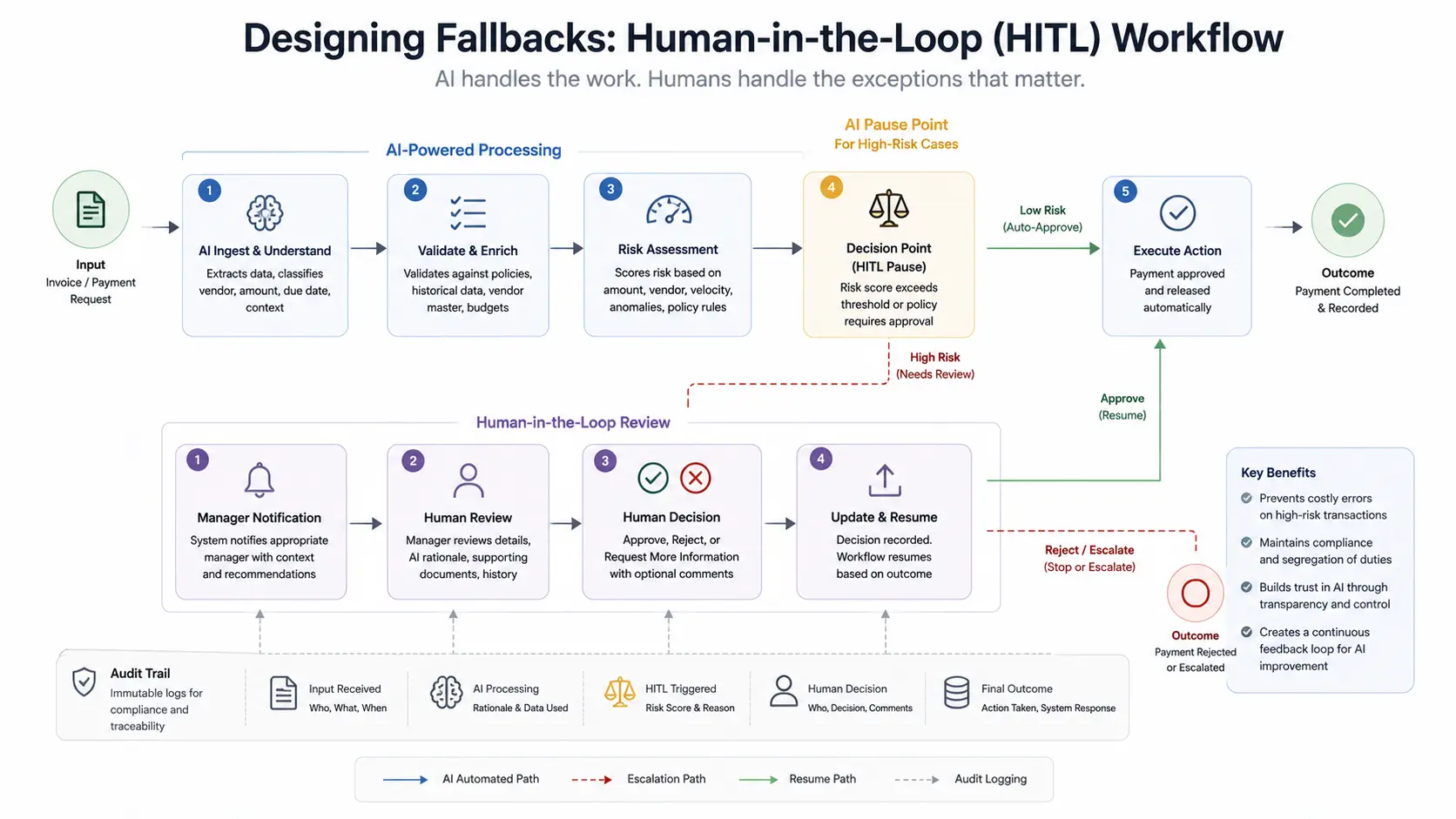
The JSON is matched against open POs in the ERP. Matched invoices below approval threshold auto-queue for payment. Discrepancies (price variance >2%, missing PO reference, duplicate invoice number) route to HITL review queue.
Outcome
Straight-through processing rate of 70–85% on typical vendor invoice sets. Finance team reviews exceptions only. Audit log captures the full extraction-matching-decision chain for every invoice processed.
Blueprint 2 Semantic Customer Support Routing
Support email volume scales with customer growth in a way that headcount rarely can. The operational bottleneck is not response time — it’s correct first-contact routing. A technical question routed to a billing agent, or a churn-risk signal misclassified as a standard inquiry, introduces latency and friction that compounds into measurable customer satisfaction degradation and, in high-stakes accounts, revenue risk.
📖 Production Deployment — Operations Director, B2B SaaS, 2025
An operations director managing a 12-person support team across three time zones deployed this blueprint on n8n with a Claude API extraction node. Pre-deployment, first-contact routing accuracy was 71%. Post-deployment, it reached 94% — the gap representing tickets that previously required a re-route after the first agent spent time on them. The team went from triage-heavy to resolution-focused within 60 days of deployment. No headcount reduction — the same team handled a 40% increase in ticket volume without additional hiring.
The semantic routing workflow classifies incoming messages on four dimensions simultaneously: primary intent (billing, technical, account, feature), urgency signal (SLA breach risk, churn indicators, executive escalation language), account tier (inferred from email domain or CRM lookup), and required action type (immediate response, async resolution, proactive outreach). Each combination maps to a routing decision with a specific queue, SLA timer, and response template trigger.
Blueprint 3 Automated CRM Data Enrichment
CRM data quality degrades continuously. Contacts change roles, companies get acquired, firmographic data becomes stale. A sales team working from a CRM where 30% of records have incomplete or outdated information is making qualification and prioritization decisions on flawed inputs. CRM data enrichment was historically manual (costly), or dependent on third-party data vendors (recurring cost, limited customization). Agentic AI workflows allow enrichment from first-party signals — the emails, call transcripts, and engagement data your organization already generates.
Signal Ingestion
Trigger on new email thread, closed call transcript, or contract document. Parse the communication for signals: titles and roles mentioned, business problems described, technologies referenced, decision-maker identifiers, timeline language.
LLM Entity Extraction
Extract and structure: contact’s current role and seniority inference, company initiatives described, pain points articulated, buying stage signals, competitor mentions. Returns a JSON patch object ready to write to CRM fields.
CRM Write & Confidence Scoring
High-confidence extractions (model certainty above threshold) write directly to CRM via API. Low-confidence fields (ambiguous context) are flagged for sales rep review in a daily digest rather than auto-written. This prevents bad data from propagating.
AI CRM Workflow ROI
Typical outcome: CRM record completeness rises from 40–50% to 80–90% within 90 days of deployment. Sales qualification time drops because reps are reviewing enriched records rather than building context from scratch before each call.