Understanding the Answer Engine: How Perplexity and Gemini “Think”
The shift from keyword matching to entity-based retrieval — and why it changes everything
Answer Engine Optimization begins with a precise understanding of how Retrieval-Augmented Generation (RAG) systems actually process a user query. When someone asks Perplexity “what is the best framework for microservices communication,” the system does not run a keyword match across indexed URLs. It encodes the query as a vector — a mathematical representation of its meaning — and retrieves the passages whose semantic embeddings are most proximate in a high-dimensional vector space. The page that gets cited is not the one that contains the most instances of “microservices communication.” It is the one whose semantic content most precisely satisfies the query intent in a form the RAG system can extract and synthesize.
This is the fundamental architectural shift underlying AEO optimization. Traditional SEO operated on a document-level retrieval model: rank a URL, and the user clicks through to the page. AI answer engines operate on a passage-level retrieval model: extract a semantically coherent chunk from the document, synthesize it with other passages, and present a composed answer with inline citations. Your page may never receive a direct click — but it may generate significant brand exposure as a cited source within AI-composed responses.

RAG systems typically split content into chunks of 200–500 tokens. Each chunk is independently embedded and retrieved. This means every paragraph must be semantically complete — capable of conveying a coherent, citable claim without relying on surrounding context. A paragraph that says “As mentioned above, this approach works because…” will never be cited. A paragraph that opens with a standalone definitional claim and supports it in the same block will.
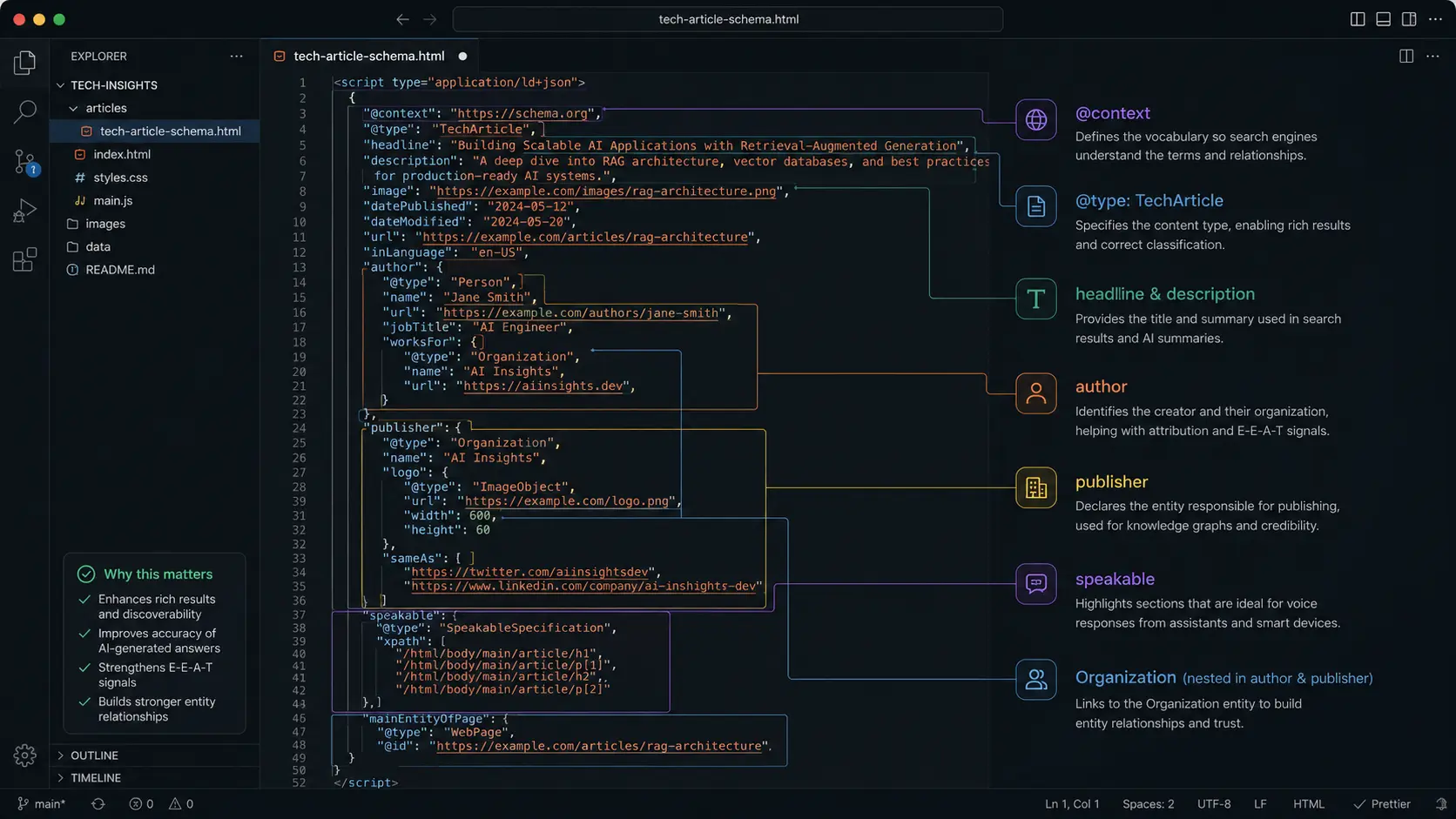
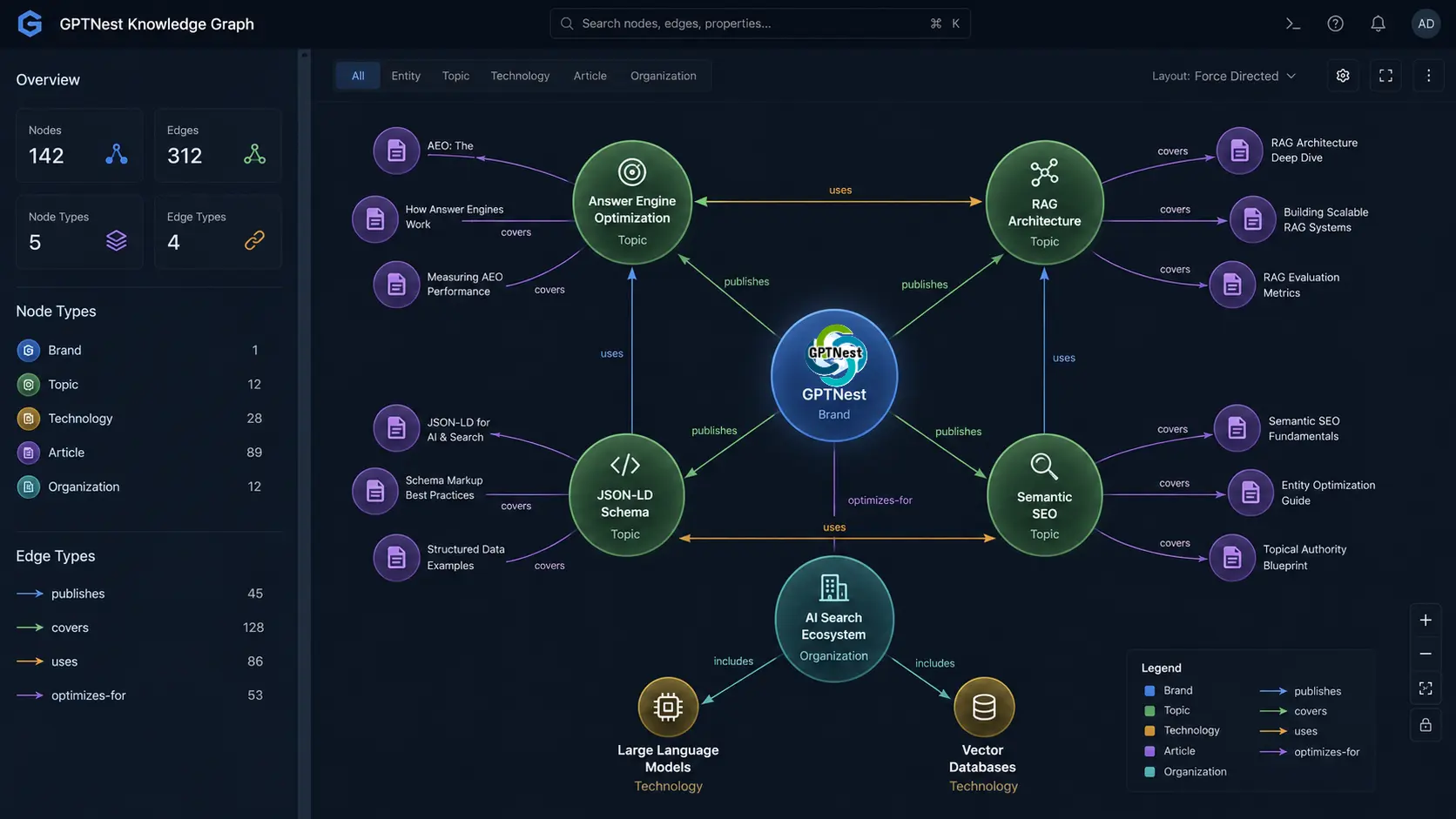
In a keyword model, “RAG architecture” on a page is a ranking signal. In an entity model, “RAG architecture” is a node in a Knowledge Graph with typed relationships: it is-a Retrieval Method, it uses Vector Database, it is-used-by Large Language Models. Content that makes these relationships explicit — through semantic structure and machine-readable markup — is classified more accurately and retrieved more reliably than content that simply mentions the terms.
💡 Architectural Insight
Google AI Overviews, Perplexity, and SearchGPT all use variants of the same underlying architecture: dense vector retrieval followed by LLM-based synthesis. The specific implementation details differ, but the implication for content strategy is identical — write for the paragraph, not the page. The atomic unit of AEO is the semantically complete, citable statement.