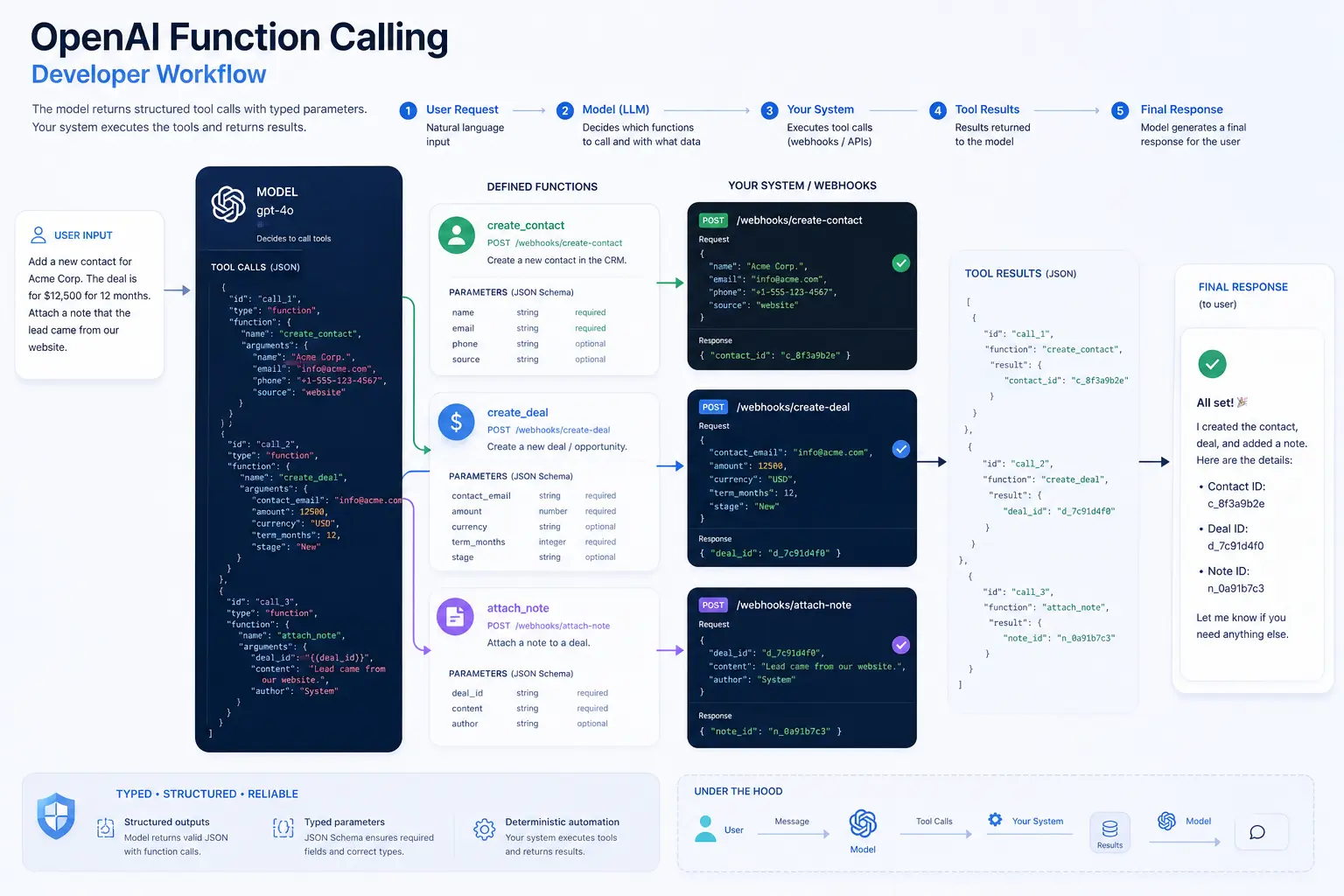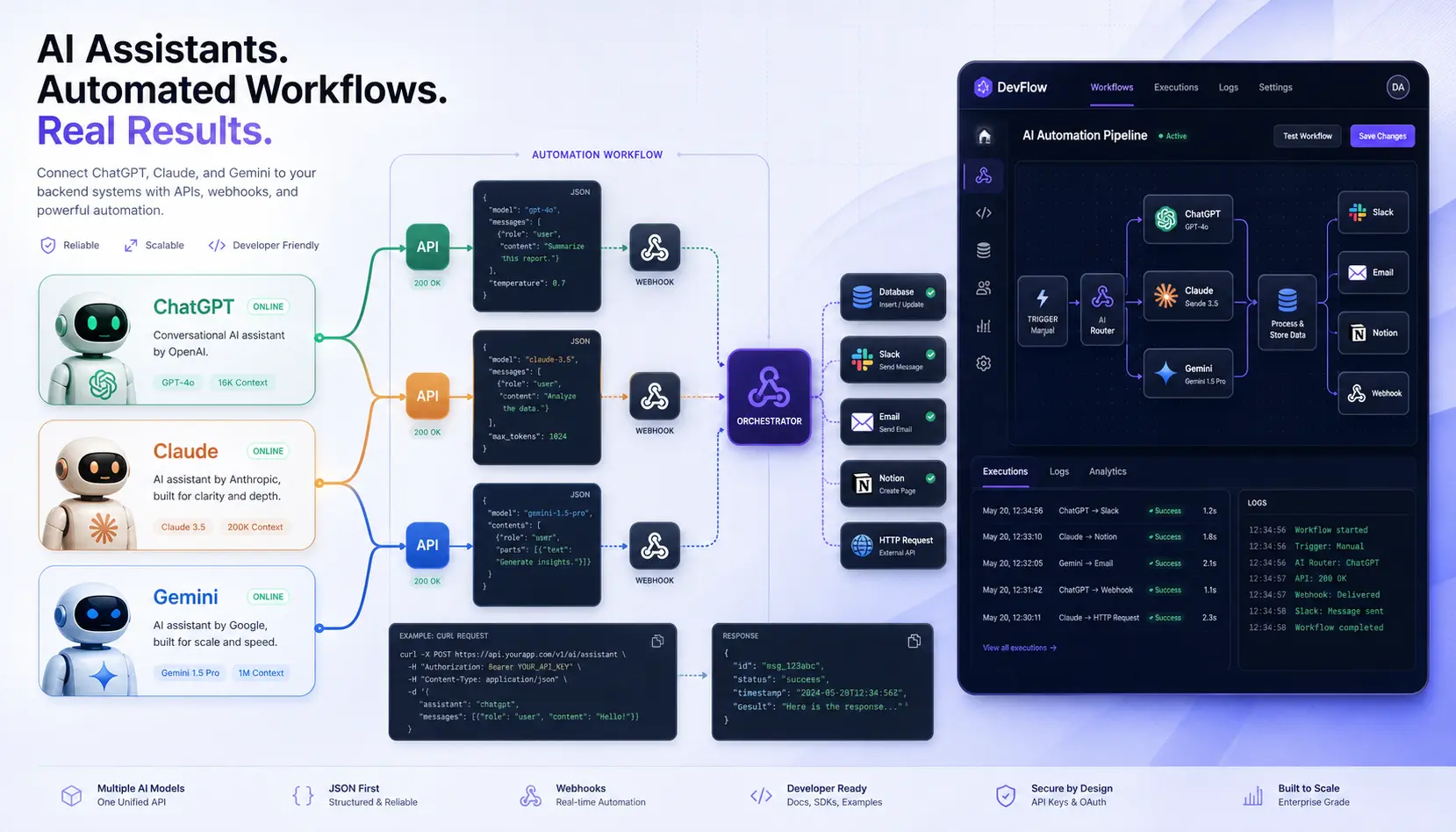
The Core Criteria for Automation APIs
Reliability, Speed, Cost, and JSON Strictness — the only metrics that matter in production
Evaluating LLMs for automation is fundamentally different from evaluating them for end-user chat. A chatbot that occasionally produces a verbose or off-tone response is merely annoying. An automation API that intermittently drops required JSON fields, hallucinates function parameter values, or times out under load is a production incident. The evaluation criteria must reflect that gap.
Four criteria dominate every serious ChatGPT vs Claude API (and Gemini) selection for backend workflows: JSON output strictness (does the model reliably produce schema-valid output?), function calling fidelity (are tool parameters consistently typed and within defined enums?), latency profile (p50 and p95 TTFB under realistic load), and token economics (combined input/output cost per million tokens at your expected mix). Rate limits — RPM and TPM per tier — function as a system architecture constraint that shapes queue design before the first line of infrastructure code is written.
A model’s JSON mode or structured output feature must be tested against your actual schemas — not toy examples. Nested arrays, optional nullable fields, and enum-constrained strings are the failure points. Test with at least 500 calls before committing a provider to a critical pipeline path.
The critical test is parallel tool calls: does the model correctly invoke multiple tools in a single turn with non-hallucinated arguments? Models that drop tool calls under context pressure or invent parameter values outside defined schemas create silent failures that are difficult to detect without thorough output validation.
⚠️ Critical Note
Rate limits vary significantly by tier and organizational account age. All figures in this guide reflect publicly documented Tier 2–3 limits as of May 2026. Enterprise agreements offer higher ceilings but require direct negotiation. Always architect for the limits you have on day one, not the limits you expect to negotiate later.